The Current Data Stack is Too Complex
In a new survey, 70% of data leaders & practitioners warn complex data stacks are the biggest barrier to AI adoption.
Written by Animesh Kumar, Saurabh Gupta, and Matt Lampe | 9 min • April 15, 2025




*Required
We'll send you the latest news.
The Current Data Stack is Too Complex
In a new survey, 70% of data leaders & practitioners warn complex data stacks are the biggest barrier to AI adoption.
Written by Animesh Kumar, Saurabh Gupta, and Matt Lampe | 9 min • April 15, 2025
CEOs now recognize that AI's transformative potential hinges directly on having a well-executed data strategy. Without a comprehensive strategy with executive support, C-level ambitions to "do something" with GenAI/General AI have a high probability of failing, according to Forbes.
While it may seem intuitive to simply make the existing data management tools and solutions work better, a new survey conducted by startup The Modern Data Company in collaboration with the MD101 community highlights a problem with that thinking.
According to more than 230 seasoned data practitioners and leaders from across 48 countries, data stacks are too complex — and a hinderance to a robust data strategy. This means CXOs must apply their influence through budgets and top-down support to change the way their companies manage data to meet AI needs.
Many respondents shared the struggles with overly complex solutions, which fundamentally limit which AI use cases can be pursued. The survey suggests that forward-thinking CXOs should restructure teams around business domains, rather than technology and tool specializations, as one way to tackle this problem.
Companies focused on cultivating T-shaped professionals (with both deep expertise in core platforms as well as broader knowledge) can develop institutional problem-solving capabilities to substitute excessive tooling. A strategy that specialized teams simply cannot perform against.
Eliminate data complexity. Learn how to simplify management, enhance security, and drive innovation in this on-demand webinar.
The modern data stack (MDS) brought around a lot of positive momentum, including the shift to cloud ecosystems, which reduced barriers to entry and made data not just more accessible but also recoverable.
But with MDS, vendors and providers were overcome with solving small bytes of the big-picture problem, which was indeed the need of the hour. This tooling proliferation, especially from vendors, was catalyzed by some (among many) of these factors:
Specialization over generalization: Specialized tools solved niche data challenges and created silos.
Lower barriers to entry: Cloud and SaaS reduced costs and accelerated tool adoption.
Varying vendor-champion partnerships: Changing leadership with differing tool preferences and independent team decisions led to an uncoordinated tool stack.
Lack of end-to-end organizational data strategy: Immediate fixes took priority. Tools were adopted to solve immediate problems without considering long-term scalability or integration.
Siloed tools were intended to become a modular network of solutions that users could interoperate to solve larger problems. However, the modern data stack has become a double-edged sword. The maze of integration pipelines, which only a few star engineers with years of institutional knowledge in an organization understand, imply both a technical and cultural centralization of key data assets and solutions.
According to the survey, users now spend one-third of their time jumping between tools. About 40% of the respondents spend more than that amount of time jumping from one tool to another, ensuring the tools work well together.
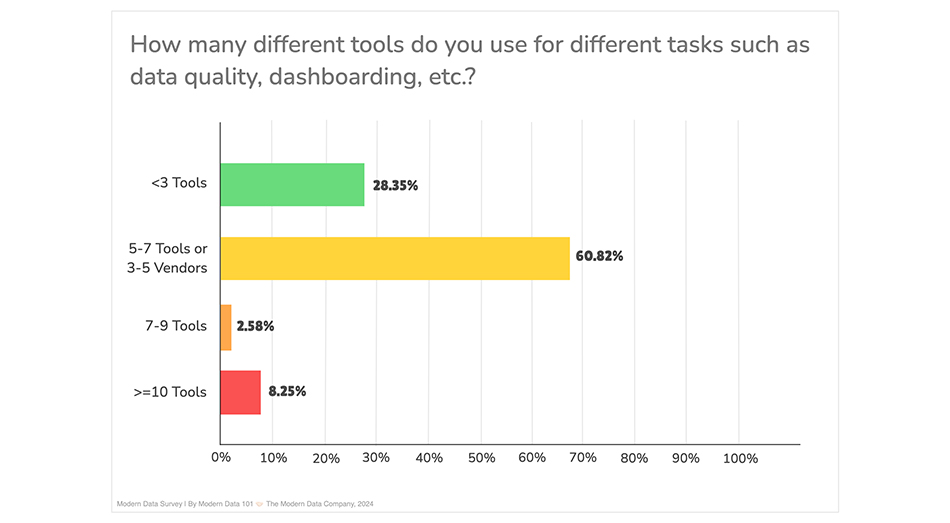 Modern Data Survey, 2024 | The Modern Data Company
Modern Data Survey, 2024 | The Modern Data Company
Imagine the amount of time teams spend just to stay afloat in a fragmented tooling landscape: troubleshooting integration bugs, patching up connections between tools that were never designed to work seamlessly together, ongoing maintenance, performing detailed lineage tracking, and manually following the trail of data across multiple systems to confirm its validity.
The result? Valuable time and resources spent on overhead tasks, rather than on the insights and actions that drive value.
For AI initiatives, this resource drain could be deadly to future success and buy-in.
It takes time for decisions to take effect. Each tool means patience and investment of not just resources, but time.
Given the fundamental design flaw of “adding one more tool,” what follows is overhead around maintenance, integration, licensing, and opportunity costs specifically due to the investment of time.
Ultimately, the end objective of getting closer to business value is pushed further away when maintenance and integration precede core data development. More data integration tools are added to the equation to solve the gaps, and the cycle continues.
"40% of respondents stated that maintaining integrations between various data tools leads to the highest costs. "
And picture this—with every iteration of new niche tooling, in addition to licensing costs for every tool, there are also additional hidden (huge) costs of premium in-app feature purchases. But much more problematic is the added maintenance cost that each tool incurs. In fact, about 40% of respondents stated that maintaining integrations between various data tools leads to the highest costs.
The cost of owning the tool significantly increases when, on top of licensing and service, an additional 15-18% is maintenance cost. If a business is spending $2M on a contract, plus $300K in additional maintenance costs, the negative impact on ROI is huge.
With data flowing (read: duplicated) between multiple tools across different domains (preferred native stacks), there is unchecked corruption. It’s increasingly difficult to track the lineage and root cause of corruption as the proliferation of tools continues.
More often than not, business users prefer to simply duplicate data instead of spending hours or weeks waiting for the integration bridge to get fixed or renewed. This comes from a deficit in awareness of the implications of data duplication or corruption, and also the frustration from time lags and inefficient data supply to business use cases.
Without proper integration bridges, there’s no stable model that data developers and business users can rely on. Instead, a legacy model with incomprehensible branches is branched out every time a new requirement comes in, facilitating the immediate need for a new tool pipeline or answering a new business query/request.
With abundant tooling, it is becoming increasingly difficult for organizations to focus on solution development that brings in business results, since consistent attention is drawn by maintenance tickets.
"Data and analytics engineers are stuck in a maintenance-first, integration-second, and data-last culture. "
Data and analytics engineers are stuck in a maintenance-first, integration-second, and data-last culture. This involves countless hours spent on solving infrastructure drawbacks and maintaining debt-ridden data pipelines. And the infrastructure required to host and integrate multiple tooling is no less painful.
Every tool has its own design language based on its own design philosophy and approach. This implies different languages, formats, frameworks or lifecycles. As a result, interoperability is much more complex and selective, and enforces steep learning curves to make things work consistently.
End-users who expect value from the tools, or data engineers responsible for making the tools talk to each other, are expected to learn the design approach of each. Even if this was simple, the need to learn the workarounds for five to seven tools and integrate them in a user-friendly way adds to huge cognitive overload.
The issue of burnout for data practitioners is more pressing considering capabilities of niche tooling are too specific for 80% of use cases, according to survey respondents, meaning that the vast amounts of time spent on maintenance is probably unnecessary.
When systems are pieced together without a cohesive strategy, managing their many moving parts becomes overwhelming. This complexity spills over, making it harder for end users to access the data they need.
Teams like marketing, sales, and support often must jump through hoops to retrieve even basic insights. Meanwhile, the central data team becomes overloaded with requests, leaving the organization struggling to clear bottlenecks and share the workload across domains.
This is where the early data mesh movement put the spotlight on domain ownership—a shift toward decentralization. The idea is appealing: let individual teams manage their own data.
But how practical is this approach in the real world? When applied to a functioning business, a few key challenges start to emerge:
Not enough skilled professionals to allocate to each individual domain. Practically, how economically viable is the idea of having data teams and isolated data stacks for each domain?
Not enough professionals/budget to disrupt existing processes, detangle pipelines, and embed brand-new infrastructures.
Not enough experts to train and onboard during the process and cultural migration.
Decentralization is both a skill and resource-deficit issue. Moreover, with decades spent on evolving data stacks with not much value to show, organizations are not ideally inclined to pour in more investments and efforts to rip and replace their work.
The intention of siloed tools that targeted specific problems was to become a modular network of solutions that users could interoperate to solve larger problems. However, this approach is flawed.
"Tools that target specific problems do not act as the simplest unit of solutions. They’re actually large solutions themselves, directly targeting big chunks of the problem. "
Modularity comes from having the simplest form of solutions available as independent building blocks that could be put together in a desirable combination to act as larger solutions. The tools that target specific problems do not act as the simplest unit of solutions but are, in fact, large solutions themselves, directly targeting big chunks of the problem (e.g. Data Quality or ETL).
Each component of this already large solution (i.e. a tool) does not know how to talk directly to other large solutions (base components of one tool cannot be reused in other applications or solutions). Instead, the whole tool needs to be used through a complex integration with all its very specific design and workflow nuances.
There are two keys to this problem.
The first key is nondisruption. The question is how can a business cut losses from tooling overwhelm without adding more disruption to the data team’s or the domain team’s plate? In other words, how can the experience of existing native stacks be enhanced?
The second key is modularization. This enables cross-domain reusability and cuts down integration overheads. In other words, unifying the approach to work and tools. Modularization, which means splitting a large problem into the lowest forms of independent solutions, enables the unification of the data stack. Note that “splitting” and “unification” are in the same sentence. On the other hand, large solutions (niche tools) contribute to more siloes by withholding data and base components within stricter boundaries.
By careful analysis of many implementations, the survey found that lego-like modularity, enabled by unified data platforms, leads to:

This is in huge contrast to traditional data stacks, which are a collection of tools forced to talk to each other through complex and highly time-consuming integrations.
To learn more about these insights, and additional solutions to the complex data stack problem of today, read the full survey by The Modern Data Company in Modern Data 101.

Contributor
Animesh Kumar is the CTO and Co-Founder of The Modern Data Company. He also founded Modern Data 101, a global community of data product leaders and practitioners from 130+ countries and counting. With over 20 years in data engineering, Animesh has donned several hats, including Architect, VP of Engineering, CTO, and Founder. In due course, he has architected data solutions for several A-Players, including NFL, GAP, Verizon, Rediff, Reliance, SGWS, Gensler, TOI, and more.

Contributor
Saurabh Gupta heads Revenue and Strategy for The Modern Data Company. He has led and executed large strategic initiatives, managed portfolios, established data governance frameworks, data standards, and operating models, and driven change within diverse and political environments, working with international organizations such as IMF, World Bank, AFDB, ThoughtWorks, and UNDP.

Contributor
Matt Lampe is the Customer Success Director at The Modern Data Company. Matt brings over 20 years of experience and has worked with a wide range of companies, including industry leaders like GAP, Slalom, and Hitachi. Matt works across Product, Engineering, Architecture, and C-suite to create strategies and then build and execute plans to deliver results.