AI is Magic... Sort Of
Why large reasoning models might be little more than a hat trick.
Written by Joe Chapa | 7 min • June 30, 2025





*Required
We'll send you the latest news.
AI is Magic... Sort Of
Why large reasoning models might be little more than a hat trick.
Written by Joe Chapa | 7 min • June 30, 2025
“Magic doesn’t fool you because you’re stupid,” Penn Jillette said on The Jonathan Ross Show in 2019. “Magic fools you because it’s stupid…The human brain wants to have beautiful, wonderful experiences. So, if you want to fool somebody, you come up with something really, really stupid.”
Jillette then brought comedian Rebel Wilson onto the stage and through misdirection and sleight of hand, managed to perform an illusion that was transparent to everyone in the room and even to everyone at home, but not to Rebel Wilson. As Jillette put it, Wilson got to see the magic. We got to see the stupid.
Jillette wasn’t offering commentary on the state of large language models (or large reasoning models) in 2025, but he might as well have been.
Learn how to take a methodical approach toward trustable AI success.
Two recently released papers argue that what industry has been calling “reasoning” isn’t really reasoning at all.
In Apple’s recent paper, The Illusion of Thinking, researchers compared the performance of large language models against the performance of language reasoning models. So these pairings pit, for instance, Anthropic’s Claude 3.7 against Claude 3.7 with “extended thinking mode;” and it compares Gemini against Gemini Thinking and DeepSeek-V3 against DeepSeek-R1, etc.
The tasks under consideration were puzzles of varying complexity. Here’s just one example.
Do you remember the baby or toddler toy that has a single peg with several disks of different colors and sizes? When the disks stacked in order with the largest on the bottom the stack is sort of shaped like a Christmas tree. There’s a well-known logic puzzle call the Tower of Hanoi that presents participants with a similar peg and stacked disks, except the disks are stacked randomly. Then there are two other empty pegs available to the participant. The disks can be moved from the original stack to one of the two other pegs. Ultimately, the participant is supposed to produce a stack in order from largest at the bottom to smallest on top. This is one of the tasks the Apple researchers gave the models. By adding or removing disks, the researchers can throttle the complexity of the task.
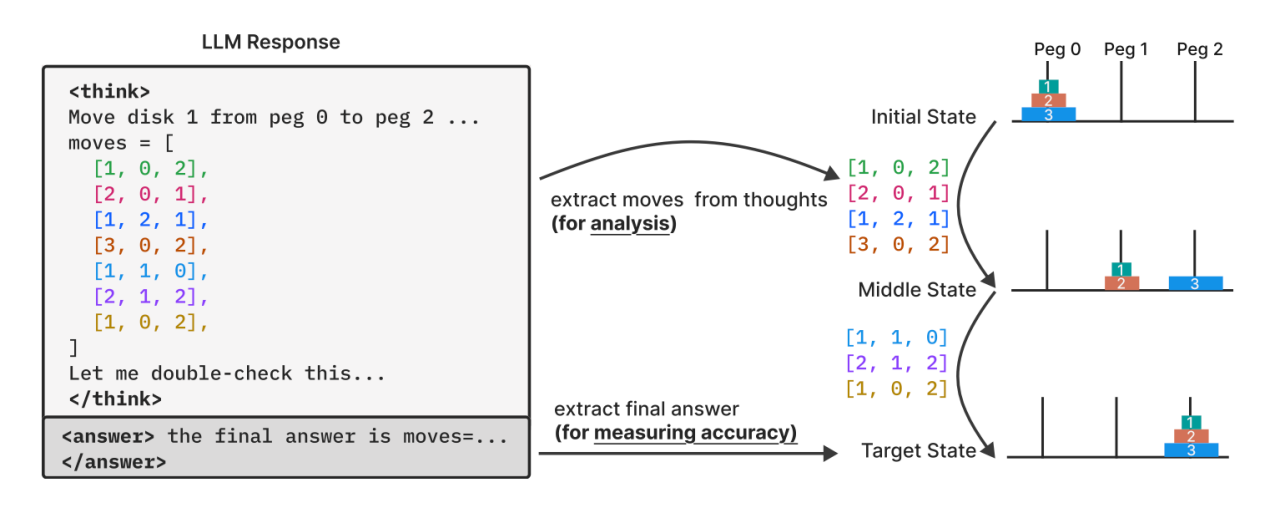 Shojaee, et al., “The Illusion of Thinking” Apple, page 2.
Shojaee, et al., “The Illusion of Thinking” Apple, page 2.
As is often the case in papers with flashy titles, the substance of the paper’s conclusions don’t really live up to the title’s hype. The researchers didn’t really show that reasoning in large reasoning models is illusory.
What they did find was that in puzzles of varying complexity, model performance can be categorized into three different regimes.
"If you use a large reasoning model on a simple reasoning task, not only are you more likely to get the answer wrong, but it’s also going to cost you more to do it. "
In simple tasks, the non-reasoning models out-performed the reasoning models in both accuracy and efficiency. The researchers found that in simple tasks, even when the reasoning models did land on the correct answer, they continued to try alternatives. This inefficiency, combined with the fact that large reasoning models already employ computationally expensive chain of thought processes, means that the computing cost for a given simple task is higher for large reasoning models than it is for the large language model without “reasoning” capabilities. So, in this regime of simple tasks, the finding is a kind of double-whammy.
In moderately complex tasks, the reasoning models did tend to arrive at the correct answer more often than the non-reasoning models, but only after considering lots of false alternatives. Here, there is a tradeoff between accuracy and efficiency. In other words, you can use a large reasoning model to arrive at the right answer to a moderately complex reasoning task, but it’ll cost you.
Finally, for both large language models and large reasoning models, the researchers found that beyond a certain complexity threshold, model performance collapses. For example, when the researchers used Claude 3.7 to solve the disk task, the large language model by itself was able to conduct the task with only three disks, but it was unable to do it with any more than three. The large reasoning model version could do up to six, but beyond that, its performance collapsed, too.
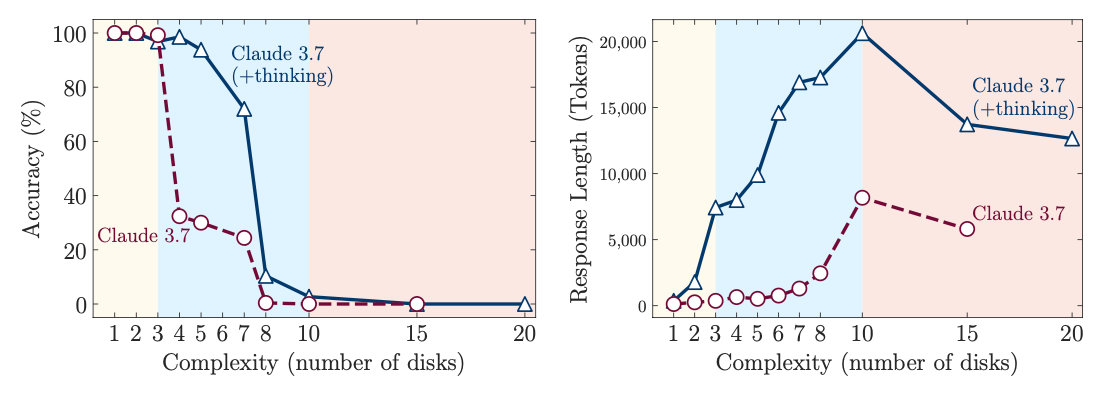 Shojaee, et al., “The Illusion of Thinking” Apple.
Shojaee, et al., “The Illusion of Thinking” Apple.
One of the most important findings in the paper is that even when the researchers gave the model the answer, that didn’t improve performance. For instance, there is a known algorithmic solution to the Tower of Hanoi puzzle. It’s a series of sequential steps that ultimately yields the right solution for the task. When researchers provided that algorithmic solution in the prompt, the large reasoning models did not perform any better than when they weren’t given the algorithmic solution. One tested solution is to generate Chain of Thought (CoT) in an artificial neural network prior to the final answer — but obtaining high-quality, scalable CoT data is scarce and expensive. Reinforcement learning is another approach, albeit contested, with some researchers questioning if this training method truly elicits unique lines of reasoning.
So, what can we learn from this paper? The answer is summarized nicely in a second paper published at about the same time. As Jintian Shao and Yiming Cheng put it in their paper, [Chain of Thought] is Not True Reasoning, “by forcing the generation of intermediate steps, Chain-of-Thought (CoT) leverages the model’s immense capacity for sequence prediction and pattern matching, effectively constraining its output to sequences that resemble coherent thought processes.”
In other words, large language models—even their close cousins, large reasoning models—are not actually doing what you and I do when we reason, much less with high accuracy. They are only imitating the words that we use. And yet, by imitating the words that we use, they are able to mimic human reasoning.
“It is not the case that there’s nothing to see here,” Shao and Cheng write. “But it is also not the case that AI is on the verge of human-level performance.”
The capability made possible by generative AI, including so-called “reasoning” models is real and its important. But it is also limited. I know there are lots of voices out there who think that, in very short order, we’ll be able to use generative AI to solve the world’s hard problems. What the Apple researchers showed empirically, and what Shao and Cheng argued theoretically, is that the performance of foundation models—even large reasoning AI models—depends upon access to the relevant problems in the training data. And that deep learning algorithms may even be hitting a wall.
How are we able to judge these models’ performance on puzzles like the Tower of Hanoi and River Crossing? Because we humans have already solved those puzzles. We are just not anywhere close to being able to feed generative AI the world’s hardest problems—solving world hunger, managing nuclear deterrence, or building a plan for the climate—and then just hitting the “I believe” button when we get the outputs.
It’s like Penn says (sort of): AI doesn’t fool us because we’re stupid. Our brains just want to have these beautiful, wonderful experiences. When we see AI do something that looks so human, like reasoning, we want to believe its reasoning. But these papers (and many other ls like them) are like Penn Jillette showing us how he does the trick. Next token prediction is still just next token prediction — even when it’s really good.
This article originally appeared in Views Expressed, a Substack blog. Image credit to Joe Chapa.

Contributor
Joseph Chapa is an officer in the U.S. Air Force and holds a doctorate in philosophy from the University of Oxford. His areas of expertise include just war theory and the ethics of artificial intelligence. He has previously served as the Department of the Air Force’s first Chief Responsible AI Ethics Officer. You can read his newsletter on philosophy and technology, Views Expressed, at https://chapainsights.substack.com.